There's a moment in every dependency when you realise you've crossed a line. Not the line where you use something regularly. The line where you can't imagine working without it — and where the bill for that dependency starts to become visible.
April 2026 was that moment for a lot of software developers.
The Budget Is Gone. It's May.
The story that shook me most last month wasn't a new model release or a research paper. It was a quietly circulating report about Uber: as of April 2026, they had already consumed their entire 2026 AI infrastructure budget. Gone. In four months. The culprit wasn't some rogue science project — it was ordinary developer tooling. The accumulated token usage from AI coding assistants, spread across engineering teams, had blown through projections so completely that CTOs across the industry started asking the same uncomfortable question at the same time: how did we not see this coming?
The answer, of course, is that the cost per interaction seemed trivial. Five cents here. Twenty cents there. The problem with very small numbers multiplied by very large populations doing very frequent things is that the arithmetic catches up with you fast, and it tends to catch up all at once.
I'm watching this play out in real time. I'm watching it in my own invoices.
I Am Dependent. Let Me Be Honest About That.
For the better part of the past year, Claude Code has been my primary development environment. Not a plugin. Not a helper. My environment. The place where architectural conversations happened, where boilerplate dissolved, where I'd describe the shape of a problem and work through it in dialogue before writing a single line.
I am not embarrassed to say that it changed how I work at a fundamental level. It changed how I think when I'm building things. And that, I suspect, is the exact dependency that nobody who sold us these tools wanted to talk about in the brochure.
So when the quality started fluctuating — and it has, noticeably — I had to look for alternatives. Not to replace the workflow, but to hedge it.
I've signed up to Cursor. I'm evaluating it properly, not just kicking the tyres. It's good. Different in character from Claude Code, but genuinely good.
And I've been running local models.
The Reverse Centaur Problem
Before I get to the good news about local models, there's something I want to name honestly, because I think it matters for how we evaluate this whole dependency question.
My friend Aaron Gustafson pointed me to a piece by Cory Doctorow in The Guardian that introduced a framing I haven't been able to shake: the reverse centaur. In automation theory, a "centaur" is a person assisted by a machine — the human leads, the AI amplifies. A reverse centaur inverts this: "a machine head on a human body, a person who is serving as a squishy meat appendage for an uncaring machine." Think of an Amazon delivery driver whose route, pace, and every eye movement is dictated by the AI cameras surrounding them. The van drives the driver, not the other way around.
Doctorow's radiology example is the one that really landed for me. The AI sales pitch to a hospital CEO goes like this: fire nine out of ten radiologists, have the remaining one rubber-stamp AI diagnoses at superhuman speed — and when the AI misses a tumour, it's the radiologist's fault, because they're the "human in the loop." Their signature is on the diagnosis. As theorist Dan Davies frames it, that's not oversight. That's an accountability sink: a human positioned not to catch errors, but to absorb blame for them.
Aaron put it concisely: "The promise is always that AI will help people do their jobs better. The deployment story, far too often, is that a human gets stuck reviewing machine output at impossible speed while absorbing the blame when things go wrong. That's not augmentation; it's a liability dump."
I've seen both ends of this. In my own workflow, I've genuinely been the centaur — AI amplifying judgment I already had. But I've also watched teams implement review pipelines where the human in the loop has three seconds per decision and no practical ability to override. That human isn't empowered. They're insulated liability.
When a CTO asks why the AI budget is gone, they're looking at token spend. They're rarely asking whether the people consuming those tokens are being augmented or just made complicit in machine decisions at scale. Both questions deserve an answer.
April Was Extraordinary for Local LLMs
I don't think I've seen a month like April 2026 for the sheer volume of capable local models being released, updated, and benchmarked. It felt like a dam had broken.
The models running on local hardware — on a decent GPU or even Apple Silicon — have crossed a threshold that felt theoretical twelve months ago. Not "impressive for a local model." Just impressive. The gap between frontier API models and what you can run privately has narrowed dramatically, and for a growing set of real development tasks, local is now a legitimate choice.
The investment behind all of this is staggering. To give some sense of scale:
- Meta committed over $60 billion in 2025 AI capital expenditure and has openly committed to matching or exceeding that in 2026
- Microsoft crossed $80 billion in AI infrastructure investment for fiscal 2025 alone
- xAI (Elon Musk's AI company) raised $6 billion in private funding in 2024, then raised again
- Google DeepMind, Amazon, and Oracle are collectively spending hundreds of billions on GPU clusters, data centres, and research over a multi-year horizon
The global AI investment figure for 2025 crossed half a trillion dollars. We are not talking about a bubble looking for a business model. We are talking about the largest coordinated capital deployment in the history of technology — and it is producing results. The open-source ecosystem is benefiting from all of it, even the parts that were never intended to be shared.
Running a genuinely useful language model locally, with no latency, no token costs, no data leaving your machine — this was science fiction in 2023. In April 2026, it's a Saturday afternoon project.
The hedge: Local models solve the cost problem and the privacy problem simultaneously. They don't yet solve the capability ceiling problem for complex reasoning tasks — but that ceiling is rising fast.
The Status Page Problem
There's a detail I keep coming back to, and it's not comfortable to write about because I genuinely admire what Anthropic has built.
If you haven't looked at status.anthropic.com recently, spend five minutes there. Look at the incident history. Look at the degradation notices. They are a company under extraordinary load — growing faster than infrastructure can comfortably absorb, managing capacity constraints that produce real, noticeable quality variations in the service.
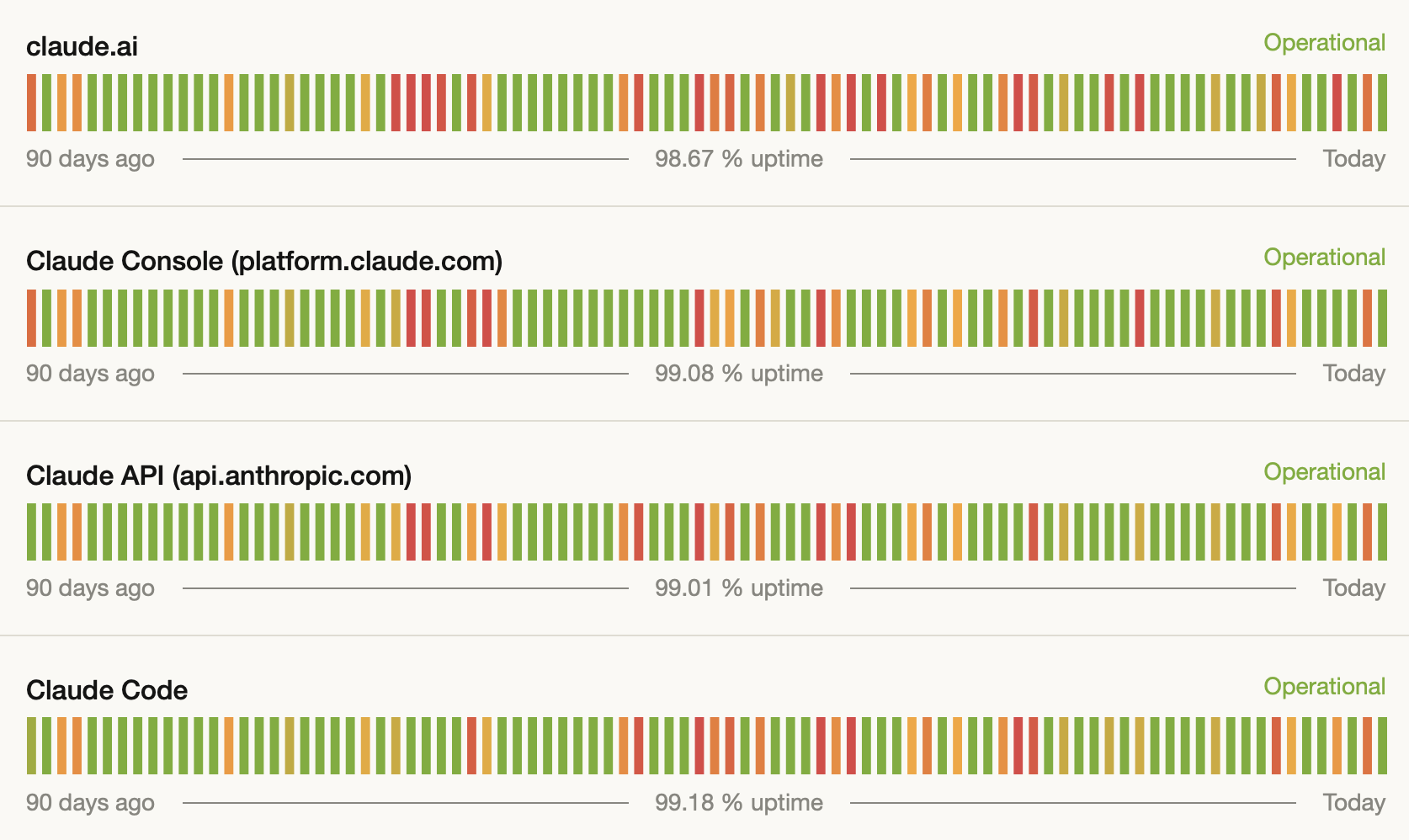
I noticed it. Most of the developers I talk to noticed it. The model that felt extraordinarily capable in early 2024 started having days — sometimes stretches of days — where responses were slower, more hedged, more likely to stall on complex reasoning. The status page would show "degraded performance" and you'd think: yes, I know, I can feel it.
This is not a criticism. It's an observation about the difficulty of scaling something this complex under this kind of demand. But it matters to the dependency question, because a tool you depend on needs to be reliable — and reliability at this scale, with this growth rate, is an engineering problem that takes time to solve.
What I Miss From March 2026
I want to be specific about this, because vague nostalgia is useless.
March 2026 was, for me, the peak of what Claude felt like as a development partner. The responses were fast. The reasoning was sharp. The ability to hold long context — to remember what we'd decided three hours ago and apply it consistently — felt genuinely different from what had come before. I was shipping things in that month that I look back on with a kind of clean satisfaction: problems solved elegantly, architecture that held together, code I could actually explain.
Something shifted in April. Whether it was capacity, whether it was a model update, whether it was traffic patterns overwhelming the infrastructure — I don't know. What I know is that the experience changed, and I felt the absence.
I'm hoping Anthropic gets back there. Not because I'm loyal to a brand, but because that version of the tool was genuinely remarkable, and I'd rather use the best tool than the most convenient one.
Nobody Has Figured This Out Yet
Here's the part I want to be honest about: I don't have a conclusion.
The AI story for software developers is not written. We are all, right now, mid-chapter — some of us mid-sentence — and the honest position is that we're learning as we go.
The dependency is real, and the costs are real. The alternatives are maturing faster than expected. The quality is variable in ways that matter. The investment scale suggests this doesn't go away. The status pages suggest the infrastructure isn't keeping up. Local models are becoming serious options. The economics haven't stabilised.
Some developers I respect are doubling down on premium frontier models and treating the token cost as a productivity investment. Others are building local-first workflows and treating API models as a fallback for the hard stuff. Most are doing something in between, awkwardly, trying to figure it out.
That's where I am. Evaluating Cursor properly. Running local models on real work. Watching what Anthropic does next. Keeping an eye on the cost curves.
The tools that felt like magic in late 2023 are now infrastructure. And infrastructure has to be managed, costed, and occasionally replaced. That's not a disappointment — it's just maturity. This technology is growing up, and we're growing up with it.
If your team is in the same position — trying to figure out the right AI tooling strategy, manage the costs, or build workflows that actually hold up — I'd genuinely enjoy talking through it. Reach out here.

Written by Kenneth Himschoot and published on May 1, 2026.